
■ はじめに
こんにちは、ネットワンシステムズ(株)ビジネス開発本部 応用技術部 所属の 山内 諒太 です。
VMware・Dell製品の技術担当として、仮想化・クラウドに関するテクノロジーの調査・検証業務に従事しています。
今回、ネットワンシステムズでは Broadcom 社と共同で vSAN ESA に関する各種試験を実施し、vSAN ESA の実力を検証しました。
VMware vSAN 8.0 から新たに実装された「vSAN ESA」は、従来からのアーキテクチャである「vSAN OSA」と比べ、I/O性能が大幅に向上し、スナップショット利用時や障害発生時のパフォーマンス影響が大きく減少すると説明されています。
本記事では様々なパターンで試した検証結果に関して皆様に紹介します。
■ vSAN ESA と vSAN OSA
vSANには、「vSAN OSA」と「vSAN ESA」の2種類のアーキテクチャがあります。
vSAN OSA(Original Storage Architecture)は、各ホストに搭載された高耐久な SSD をキャッシュ層として使用し、大容量な HDD または SSD をキャパシティ層としてディスクグループを構成する二層アーキテクチャです。2010年代に vSAN が初めてリリースされた際に一般的だった HDD を SSD と組み合せることで、HDD を利用したハイブリッド構成でも高い性能を発揮できます。
一方、vSAN ESA(Express Storage Architecture)は、vSAN 8.0から新たに導入された NVMe に最適化された最新のアーキテクチャです。このアーキテクチャでは、ディスクをすべて NVMe SSD で統一し、ディスクグループや、キャッシュ層とキャパシティ層の区別がない単一層アーキテクチャになっています。すべてのノードのすべてのディスクを高パフォーマンスなキャパシティとして使用でき、vSAN OSAと比べるとデータのアクセスパスが短縮されるため、より高いI/O性能と低遅延を実現します。

出典 : VMware vSAN 8 Technology Overview – YouTube
■ 検証の概要
本検証では vSAN ESA のストレージ性能を検証することを目的とし、以下の点に着目して検証を実施しました。
- I/O サイズ、Read / Write 比率、スレッド数等、負荷条件や通信方式 (TCP vs RDMA)、ストレージポリシー (RAID1 vs RAID5) を変化させた
vSAN ESA データストアあたり(クラスターあたり)の性能比較検証 - 1VM あたりの最大性能検証
- スナップショット利用時、および障害発生時を想定したパフォーマンス影響の検証(可用性)
なお、検証に利用したハードウェア・ソフトウェアの構成は以下の通りです。
本検証では、Dell VxRail、VE-660 を使用し、4ノードでクラスターを構成しました。
こちらは、エントリー向けの VxRail E シリーズの1つで、All NVMe SSD ディスク構成で vSAN ESA に対応可能です。
- ハードウェア:VxRail VE-660 4ノード (以下構成は1ノードあたり)
- CPU : Intel® Xeon® Gold 6400シリーズ 32 Core x 2 Socket
- Memory : 512GB
- Disk : NVME SSD (MixUse) 3TB x 4
- NIC : 100GbE QSFP x 2、25GbE SFP28 x 2、1GbE x 2
- ソフトウェア
- vSphere 8.0 u3
- vSAN ESA 8.0 u3
- HCIBench 2.8.3
ネットワークがボトルネックにならないように、vSAN ネットワークには 100Gbps の広帯域なネットワークを使用し、さらに通常の TCP に加え、RDMA (RoCE v2) を有効化した時の性能の変化を確認します。
本検証ではストレージに対する負荷テストのツールとして HCIBench を利用しました。
HCIBench は Broadcom 社が提供する HCI 環境向けのベンチマークツールです。
vSphere 環境での使用を前提としていますが、vSAN だけでなく、外部ストレージや他社の HCI ソフトウェアのパフォーマンステストにも利用可能です。2025年5月現在、Github 上で無償公開されています。
主に HCI のパフォーマンステストを自動化するために設計されており、IO負荷を発生させるベンチマークツール(ワーカー)として VDBench か FIO のどちらかを選択して使用できます。
HCIBench はワーカーを利用するためのテストVMの展開、ワークロードの実行、テスト結果の集計、パフォーマンス分析、トラブルシューティングのためのデータ収集を自動化するため、仮想環境におけるパフォーマンステストに要する工数を大幅に削減できます。
今回の検証ではワーカーとして VDBench を利用して検証を実施しました。
【検証環境の構成】
物理構成
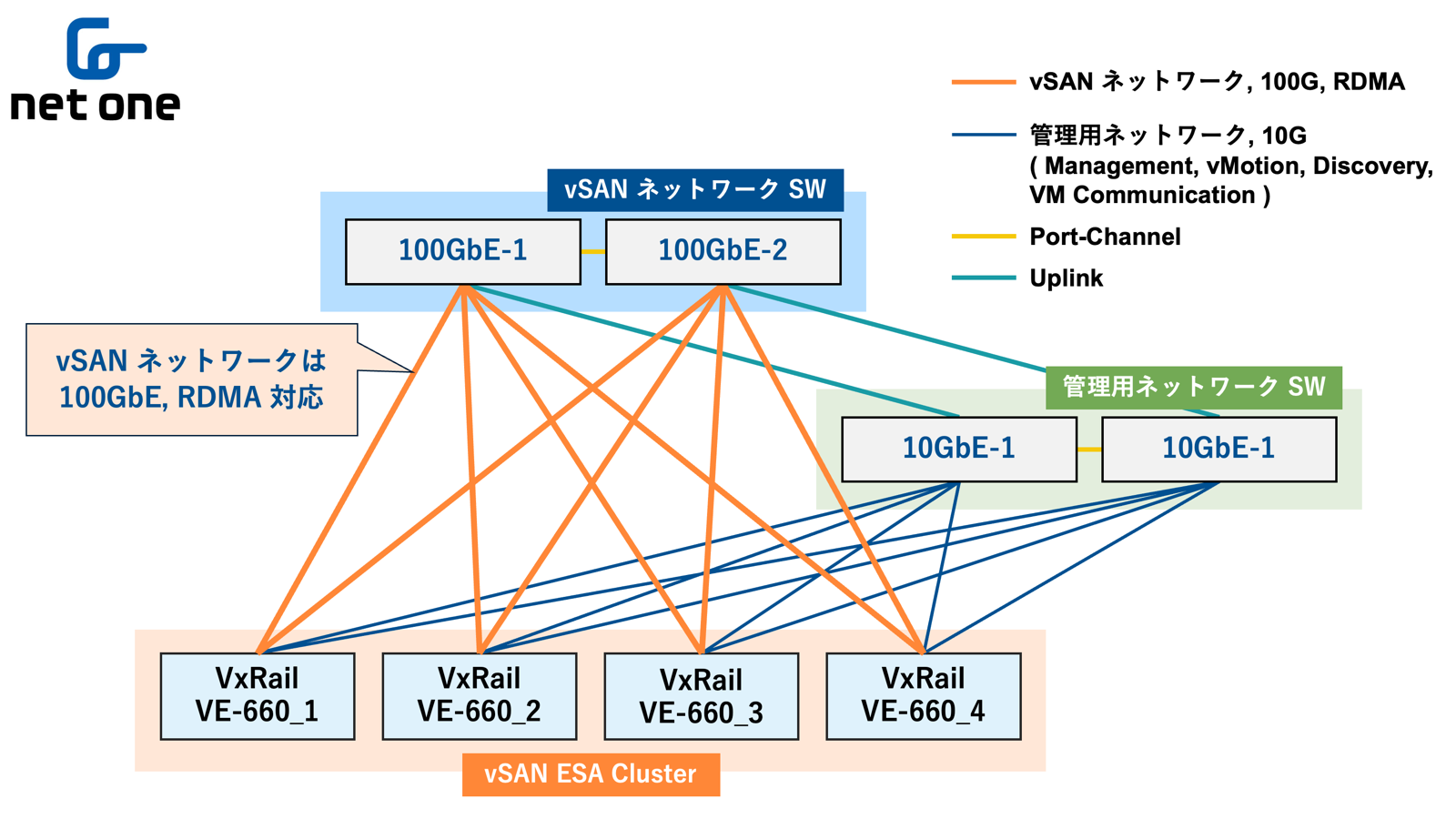
VxRail ノードは性能データのノイズを避けるためストレージネットワークと管理ネットワークを分離し、vSAN ネットワークスイッチ2台、管理用ネットワークスイッチ2台とそれぞれ接続しています。
vSAN ネットワークスイッチは、検証の I/O 処理のトラフィックが流れるネットワークで、100Gbps、RDMA 対応となっています。
管理用ネットワークスイッチは、ゲスト VM 作成や vMotion、ノード検出のためのネットワークで、10Gbps で接続しています。
論理構成
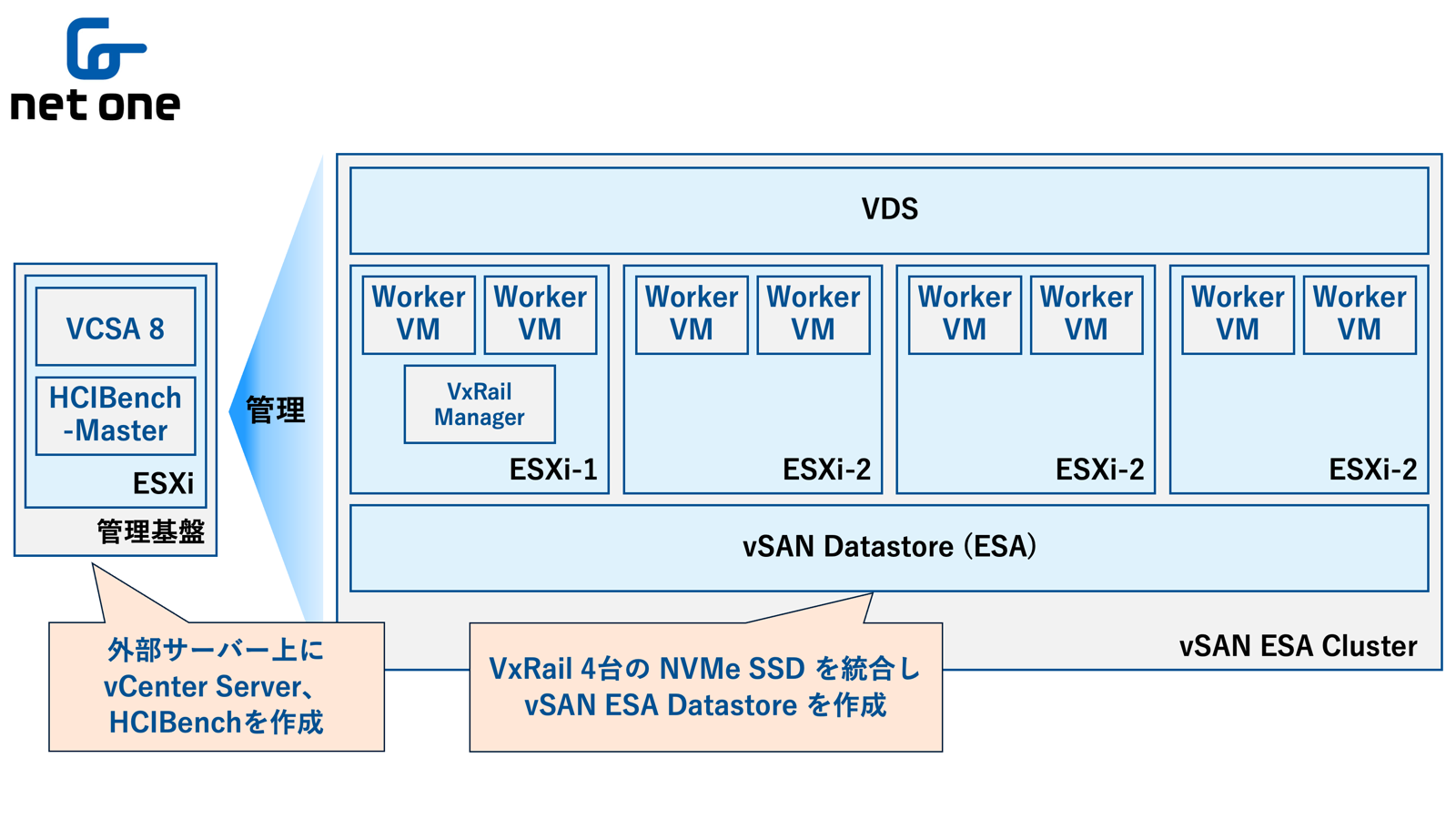
VxRail 4ノードのストレージを統合し、vSAN ESA でデータストアを構成しています。
VxRail クラスター全体を管理している vCenter Server Appliance (VCSA)、および HCIBench-Master VM は検証の負荷による影響を避けるため、検証対象の vSAN ESA クラスタとは異なる vSphere 環境に構築しています。
■ 検証内容・検証項目
【検証 1. 性能比較検証】
- Guest VM にかける I/O 負荷を 100,000、200,000、…、Max のように段階的に上げた際の IOPS、遅延(レイテンシー)を測定
- vSAN ストレージトラフィックの通信方式として TCP、RDMA の2種類を測定
- ストレージポリシーとしてミラーリング(RAID1)、イレージャコーディング(RAID5)の2種類を測定
【検証 2. 1VMあたりのMax性能検証】
- クラスター全体に Guest VM を1台作成し、Max IO 負荷をかけた場合の IOPS、遅延の測定
- 通信方式は RDMA、ストレージポリシーはミラーリング(RAID1)として測定
【検証 3. スナップショット利用時、および障害発生時を想定したパフォーマンス影響の検証(可用性)】
- Guest VM に I/O 負荷をかけている時に、スナップショット利用(取得・削除)、疑似障害発生(ネットワーク障害、ディスク障害)を行い、IOPS、遅延の変化を測定。
また、サーバーのバックエンドリソース(CPU、メモリ、ディスクなど)のパフォーマンスへの影響も合わせて調査する。
■ 検証結果
【検証1. 性能比較検証】
次の図は、同一の負荷パターンを HCIBench で実行し、vSAN ネットワークを TCP を利用した場合と RDMA を利用した場合の比較グラフです。
グラフは一例として I/O サイズ 4KB、Read : Write 比を 7:3 としています。
横軸は I/O 負荷を段階的に上げた IOPS 設定値、縦左軸は測定された IOPS (棒グラフ)、縦左軸は測定された遅延(折れ線グラフ)です。
※ ハードウェアの構成より測定される IOPS 値や各種性能値は大きく異なり、情報の独り歩きを防ぐために IOPS 値はマスクして表示していますが、4KB など小サイズ I/O では 数10万〜100万 IOPS の負荷環境においても 1ms 以下の低い遅延が計測されています。

TCP と RDMA の結果を比較すると、IOPS は RDMA の方が上限が高く、遅延は RDMA の方が低い結果となっており、RDMAの方がI/O性能の限界値が高いことが確認できます。
RDMA は TCP と比較して、Random I/O では IOPS は最大約30%向上、遅延は最大約 20% 改善、Sequential I/O では IOPS (スループット) が最大約 15% 向上、レイテンシーは最大約 20% 改善しました。
vSAN ESA と RDMA の組み合わせでは、同一ハードウェアを用いて同一負荷パターンを実行した場合においても、TCP と比較してレイテンシーの極小化と高い IOPS を実現できました。
より高性能・低遅延なストレージ I/O が求められる環境では、RDMA の利用が有効といえます。ただし、TCP に関しても実運用において必要十分な性能が発揮されているといえます。
今回、4ノードクラスターでは、Random I/O、I/O サイズ 4KB で80万を超える IOPS を 1ms 未満の低遅延で処理できています。
RDMA を利用するためには、RDMA に対応する NIC、および高帯域でロスレスな RDMA に対応するネットワークスイッチが必要なほか、有効化にはネットワークスイッチ、および ESXi ホストにて適切な RDMA 用設定が必要です。正しく有効化されていない場合、パケットロスや遅延が増加し、逆に性能が劣化する可能性があります。
そのため、限界に近い高い I/O 性能や低遅延性を必要としない場合や、RDMA の正しい設定が難しい場合は、TCP でも十分な性能が出るため TCP の利用するのが適切と考えれられます。
次の図は、HCIBench Worker のストレージポリシーを変更し、RAID1 と RAID5 のそれぞれに対しての同一負荷条件下の比較グラフです。

従来の vSAN OSA でイレージャコーディング(RAID5、RAID6)を利用すると、書き込み I/O ごとにイレージャコーディングのパリティ計算が行われるため、I/O 性能のレスポンスが劣化する課題(書き込みペナルティ・RAIDペナルティ)がありました。
一方、vSAN ESA では書き込みを行う際、最初に高速にミラーリングで書き込み仮想マシンに ACK を返し、その後非同期で RAID のストライプ幅に合わせてまとめて書き込むため、I/O ごとのパリティ計算が排除されており、イレージャコーディングにおける性能劣化が大幅に改善されています。
これにより、vSAN ESA ではイレージャコーディングを使用することで、RAID5、RAID6 の容量効率の良さを得ながら、書き込み I/O 性能は RAID1 と同等の低遅延・高速な処理が可能となっています。
グラフから分かる通り、RAID1、RAID5 ともほぼ同等の性能 (IOPS 値、遅延)となっており、vSAN ESA におけるイレージャーコーディングの利点が検証結果からも確認できます。

今回の検証で性能限界に達した原因として、I/O を生成するベンチマークツール(Worker)処理に必要なCPUリソースの枯渇が考えられます。
IOPS の増加が止まった時点のバックエンドのパフォーマンスを確認すると、ESXi ホストの CPU 使用率のみが 100% を超えていました。
NVMe デバイスの遅延や vSAN ネットワーク帯域には余裕があったため、I/O 生成における Worker VM の CPU 処理が追いつかなくなり、クラスターとしての I/O 生成の性能限界に達した可能性が高いと考えられます。あくまでもベンチマークツールを使用した超高負荷における傾向のため、実際の一般的な利用負荷では問題はないものです。
実際、4KB や 8KB の小サイズ I/O より、64KB や 128KB の大サイズ I/O では CPU 処理の上昇が穏やかで、その分 100Gb ネットワークの帯域を活かした高スループットを計測できました。
【検証 2. 1VM あたりの Max 性能検証】
次の図は、単一 VM にて計測した、RDMA、 RAID1、Random I/O、Read 70% での最大負荷を様々な I/O サイズ、並列負荷度(負荷 Threads) で掛けた検証結果グラフになります。

I/O サイズが小さいほど IOPS の最大値は大きく(逆に I/O サイズが大きいほど時間あたりのスループットは大きい)、Threads(ワーカーあたりの並列処理)が大きいほど IOPS は大きくなることが分かります。vSAN ESA が採用する NVMe デバイスは I/O Queues、Queue Depth が従来の SAS / SATA と比較して大幅に増加しており、並列 I/O 処理に強いという特徴があります。
128KB の I/O サイズにおいても 1ms 前後の低い I/O 遅延で処理ができていることが確認できるなど、vSAN ESA では様々な I/O サイズにおいて仮想マシンあたりの性能上限も高く、低遅延で I/O 処理が行われていることが確認できます。
I/O サイズが大きいと必然的に I/O ごとの遅延も大きくなるため、「遅延が大きいと性能が悪い」と一概に言えるわけではないことにも注意が必要です。大きい I/O サイズではスループットで比較することが良いでしょう。
【検証 3. Snapshot利用時、障害発生時のパフォーマンス影響の検証(可用性)】
スナップショット
次の図は、スナップショット利用時の検証結果グラフ (HCIBench Performance Monitor) になります。左図が TCP、右図が RDMA 、上段が IOPS、中断が読み込み遅延、下段が書き込み遅延を示しています。
TCP、RDMA どちらも 8 台の RAID5 構成の Worker VM に 5,000 IOPS (合計 40,000 IOPS) の一定負荷を掛けている最中にスナップショットの取得、保持、削除を行い、IOPS や遅延の変化を観察しました。

グラフより、スナップショット取得、およびスナップショットを保持した状態によるパフォーマンス影響はほとんど見られません。
スナップショット削除により、極僅かに遅延の増加が見られますが、実運用に影響はないと考えられます。TCP と RDMA でほぼ同等の結果で、vSAN ESA はスナップショットの性能影響が非常に小さいことが確認できました。遅延への影響が最大 0.05ms の増加・揺らぎが10秒程度、IOPS の増減は見られず一定を保ちました。
従来のvSAN OSAは、スナップショットの取得時や削除時に、特に高負荷 I/O 状況下でjは I/Oの瞬停 (スタン) や I/O 遅延の増加などの性能劣化が発生するという課題がありました。vSAN ESAでは、 I/O の瞬停 (スタン) はアーキテクチャ上は実行されていますが、ほぼグラフで確認できない短い間に処理が行われます。
従来のスナップショットに関する課題が解決され、明らかなI/Oの瞬停や性能劣化を心配することなくスナップショットを利用でき、メンテナンス・運用の負荷が軽減できます。vSAN 8.0 Update3 で利用可能になった vSAN ESA スナップショットを利用した vSAN Data Protection の利用も安心できると言えます。
【ネットワーク障害】
次の図は、ネットワーク障害の検証結果グラフになります。左図がTCP、右図がRDMA、上段が IOPS、中断が読み込み遅延、下段が書き込み遅延を示しています。
今回の vSAN ネットワークは2つのアップリンクをアクティブ・スタンバイの明示的なフェイルオーバー構成で組んでいるため、アクティブリンクのスイッチを切断、再接続する、ということを行いました。
スナップショットの検証と同様に、TCP、RDMA どちらも 8 台の RAID5 構成の Worker VM に 5,000 IOPS (合計 40,000 IOPS) の一定負荷を掛けている最中に上位ネットワークスイッチの片系を停止し、IOPS や遅延の変化を観察しました。

グラフより、リンクダウン時の IOPS、遅延への影響はほとんど見られません。一方、リンクアップ(ネットワークのフィエルバック)時に IOPS の増減、遅延の増加が見られます。
また、RDMAの方がTCPと比較して若干影響時間が大きくなっています。レイテンシーの増加が RDMA は TCP と比べて数十 ms ほど大きく、収束までにかかる時間も数秒長くなっています。
RDMAの方が影響が大きい原因として、ネットワークのフェイルバックから vSAN のセッション再開までのプロセスの違いが挙げられます。RDMA(RoCE v2)は、全ての vSAN ESA ノード間での UDP 上で RoCE v2 の確立によって vSAN セッションが再開されます。再開までのプロセスが若干多く、その分 TCP より Latency が大きくなったと考えられます。
とはいえ、TCP と RDMA どちらも、一般的な外部ストレージ構成のパス断時の切り替わりと変わらない性能を発揮しています。どちらのパターンにおいてもリンクアップ(ネットワークのフィエルバック)時の影響が10秒前後で収束しており、高い耐障害性が証明された結果となっています。
【ディスク障害】
次の図は、ディスク障害の検証結果グラフになります。左図がTCP、右図がRDMA、上段が IOPS、中断が読み込み遅延、下段が書き込み遅延を示しています。
vSAN ESA クラスタを構成する ESXi ホストのうち 1台のディスク1本をアンマウントすることで、人為的にディスク障害の状態を起こしました。vSANの設定として、障害発生からリビルド開始までの時間(オブジェクト修復タイマー)は3分(既定値は60分)に設定しています。
※ 通常の明示的なディスク障害では「Degrade」とディスクがマークされ、即時リビルドが開始されますが、今回の疑似障害条件では復旧見込みのある「Absent」としてマークされるため、リビルト開始までの時間を既定値の60分から3分に短縮して設定しています。
スナップショットの検証と同様に、TCP、RDMA どちらも 8 台の RAID5 構成の Worker VM に 5,000 IOPS (合計 40,000 IOPS) の一定負荷を掛けている最中にディスクの疑似障害を発生させ、IOPS や遅延の変化を観察しました。

今回の試験で特徴的なこととして、仮想マシン側にはディスク障害発生タイミングでは IOPS も遅延もほぼ変化が見られなかったことが挙げられます。
3分後にリビルドが開始され、リビルド完了まで TCP、RDMA のどちらとも遅延の増加が続きます。
リビルドに要した時間は、TCPと比較して、RDMAの方が5分程度短い結果となりました。これは、RDMAの方が仕組み上、高速かつ低遅延、並列でデータ転送を行うため、リビルドに必要なデータ転送が高速に完了したことが要因と考えられます。
とはいえ、TCPとRDMAどちらも、一般的な外部ストレージ構成以上に高速なリビルド性能を発揮しています。
今回の検証では、4ノードのうちの1ノードのディスク1本をアンマウントし、再同期対象のデータが数 TB 以上ありましたが、これらが数分でリビルド完了しています。
この性能は、一般的なユースケースで考えると十分な性能であるといえます。
検証終了の最後のマウント時にレイテンシーが僅かに増加していますが、こちらもワークロードへの影響はほぼないと考えられます。

今回の検証では RAID5 構成でのリビルドを試しましたが、RAID1 と RAID5 でのディスク障害時のリビルド時間に関しては、RAID1 の方短いと予想されます。
ミラーリング (RAID1) はディスク障害が発生したとき、通常はミラーリングされた残りのデータをコピーするだけでリビルドが完了するため、プロセスが単純で高速に処理が可能であるためです。
一方、イレージャコーディング (RAID5、RAID6) では正常なデータとパリティデータから故障したドライブ上のデータを計算し、再作成する必要があるため、プロセスが複雑で処理に時間がかかります。
■ 考察
【非常に高い I/O 性能】
弊社で実施した過去の vSAN OSA の検証結果と比較すると、構成や検証条件に差異はあるものの、vSAN ESA は大幅に I/O 性能が向上しています。
具体的には、過去に実施した同一ホスト台数、10Gb vSAN ネットワーク構成の試験と比較して、IOPS が438% に増加、読み込みレイテンシーが 26.7%、書き込みレイテンシーが 19.0%にそれぞれ減少しています。
また、vSAN ESA に RDMA を組み合わせることで、さらなる遅延の極小化と高い IOPS を低負荷で実現できることが確認されました。
イレージャコーディング環境においても、ミラーリング環境と比べて性能劣化が見られないため、容量効率が高いイレージャコーディングの利用が有効であるといえます。
【RDMA による更に高い I/O 性能の実現】
RDMAとは、リモートダイレクトメモリアクセスの略で、あるコンピュータから別のコンピュータのメモリに対して、ネットワーク越しに、CPUを介さずメモリに直接アクセスできる技術です。
CPUを介さずに、複雑なヘッダー処理がない RDMA は、高速なデータ転送、低い遅延、低い CPU 使用率という特徴があります。
今回の検証では、IOPS の伸びが止まるボトルネックとして I/O を生成する Worker VM の CPU 使用率が挙げられましたが、RDMAはTCPと比較して、CPU使用率が低いなどの特徴があるため、その分IOPS の限界値が高くなったといえます。
【高い信頼性と安定性】
スナップショットの取得・削除、そしてネットワークやディスク障害の影響が仮想マシンに対してほとんどなく、可用性が非常に高く、安定した性能が発揮できることが確認できました。
vSAN OSA と比べ大幅に性能が向上しており、バックエンド (CPU、メモリ、ディスクなど) への影響も非常に小さいことが確認できました。
性能影響を考慮することなく、スナップショットを利用することができるため、気軽にデータ保護・バックアップを実行することが可能です。また、アップデートやパッチ適用のためのステージング作業、CI/CD パイプラインなどにおいても、性能影響を考慮することなくスナップショット機能を活用することが可能になります。
障害時の影響が小さく、復旧速度が速いことで、安定したパフォーマンスを発揮できるためミッションクリティカルな環境における活用が期待できます。
■ おわりに
今回は、vSAN ESA のストレージ性能の検証結果についてご紹介させて頂きました。
昨年の「VMware Explore 2024 Las Vegas」で発表された VCF 9 のロードマップでは、vSAN ESA に「グローバル重複排除機能」や「ネイティブレプリケーション機能」が追加される予定が発表されており、より魅力的なアーキテクチャとなることが期待されています。
ネットワンシステムズでは今後も新たな機能をいち早く検証し、皆さまに価値のある情報を提供していきます。
VMware vSAN やその他 VMware 製品をご検討の際は、ぜひネットワンシステムズまでお問い合わせください。


